




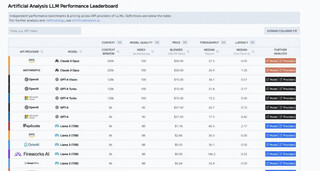
Компания Artificial Analysis разработала рейтинговую систему, оценивающую стоимость, производительность и качество более 100 LLM, чтобы обеспечить удобный выбор модели, соответствующей индивидуальным потребностям.
Разработчикам необходимо учитывать качество, стоимость и производительность при выборе LLM, и рейтинг производительности LLM объединяет все эти аспекты, позволяя принимать обоснованные решения в одном месте. Рейтинг предназначен для обеспечения комплексной системы метрик, которая поможет понять, какие модели использовать в своих приложениях для достижения оптимальных результатов.
Параметры:
Качество: комплексный индекс, рассчитанный на основе метрик, таких как MMLU, MT-Bench, оценки HumanEval, а также рейтинг Chatbot Arena;
Прайс: метрики, учитывающие цену на вход/выход на один токен, а также среднюю цену для сравнения провайдеров хостинга. Стоимость представляет собой взвешенную смесь цен на входные и выходные токены в соотношении 3:1;
Окно контекста: максимальное количество комбинированных входных и выходных токенов;
Скорость: токены/с, получаемые во время генерации моделью токенов. Median, P5, P25, P75 и P95;
Задержка: время до первого полученного токена, измеренное в секундах, после отправки запроса через API. Median, P5, P25, P75 и P95.
С помощью лидерборда можно оценить производительность при различных нагрузках: короткие (100 токенов), средние (1к токенов) и длинные (10к токенов), а также одиночные и параллельные (10 шт) промты. Одиночные промты тестируются 8 раз в день с рандомными интервалами, в то время как параллельные оцениваются 1 раз в день в случайное время.
Здесь больше метрик и в целом рассказывается про методологию.
Топ из каждой категории:
Качество: Claude 3 Opus, GPT-4 Turbo;
Прайс: $0.06/1M токенов Llama 3 (8B) через API groq;
Окно контекста: 1m Gemini 1.5 Pro;
Скорость: 912.9 токенов/сек Llama 3 (8B) через API groq;
Задержка: 0.13s Mistral 7B через API baseten.
Больше анализа и графиков AI моделей здесь.
Спасибо за прочтение! А вы уже выбрали свою модель?
Источник новости: habr.com



