




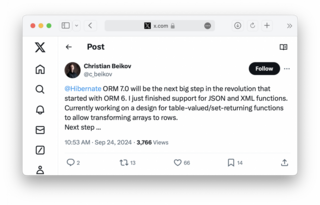
Один из разработчиков Hibernate поделился некоторыми инсайдами касаемо того, над чем он сейчас работает и какие нововведения стоит ожидать в следующей мажорной версии:Hibernate ORM 7.0 — следующий большой шаг после революции, начатой ORM 6. Я только что завершил поддержку функций JSON и XML.
Сейчас работаю над созданием функций, возвращающих таблицы, чтобы преобразовывать массивы в строки.
Следующий этап — использовать всё это в нашей реализации составных агрегатов. Независимо от того, как вы храните данные, Hibernate позволит вам моделировать и запрашивать их одинаково через HQL/Criteria. Я верю, что это изменит игру для тех, кто заботится о производительности запросов. Иерархическое хранение данных не только избавляет от JOIN (что всегда приятно), но и позволяет на некоторых базах данных создавать индексы на такие сложные столбцы! Такой подход может значительно повысить скорость поиска, например, при поиске товаров с множеством фильтров по атрибутам, таким как бренд, цвет и т.д. А в базах данных вроде PostgreSQL вы можете достичь индексного или даже только индексного сканирования для ваших запросов 🔥
Однако учтите, что такой дизайн таблиц не идеален для записи, так как отсутствуют внешние ключи, дублируются данные и т.д. — по сути, это денормализация. Чтобы получить лучшее из обоих миров, необходимо разделить модели чтения и записи.
Как только я завершу реализацию этих функций в Hibernate ORM, я покажу вам, как справиться с денормализацией 😀
Делитесь своим мнением касаемо грядущего обновления в комментариях!
Присоединяйтесь к русскоязычному сообществу разработчиков на Spring Boot в телеграм — Spring АйО, чтобы быть в курсе последних новостей из мира разработки на Spring Boot и всего, что с ним связано.
Ждем всех, присоединяйтесь
Источник новости: habr.com

 выбрать для девушки?")
