




Консорциум MLCommons опубликовал результаты отраслевых бенчмарков MLPerf Training 2.1. Набор эталонных тестов MLPerf Training оценивает производительность обучения ML-моделей, которые используются в коммерческих приложениях. Нынешний раунд включает в себя около 200 результатов от 18 различных организаций различных размеров.
Набор тестов MLPerf HPC ориентирован на суперкомпьютераы и модели для научных приложений, например, в области метеорологии, космологии, квантовой маханики, а также оценивает пропускную способность больших систем. MLPerf HPC 2.0 содержит более 20 результатов от 5 организаций. Наконец, набор тестов MLPerf Tiny создан для оценки скорости инференса для встраиваемых и периферийных систем. MLPerf Tiny 1.0 включает 59 результатов от 8 организаций, причём для 39 предоставлены данные об энергопотреблении и это рекордный показатель за всё время проведения бенчмарка.
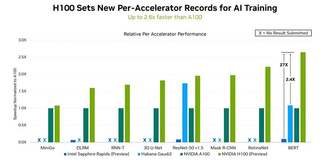
Источник: NVIDIA
В этом раунде NVIDIA восстановила лидерство, которое уступил в прошлый раз Google, благодаря ускорителю Hopper H100, производительность которого в 2,4 раза выше, чем у Intel Habana, и в 2,6 раза выше, чем у A100. В этом NVIDIA помог движок Transformer Engine, поскольку Intel Habana Gaudi 2 в тесте Resnet-50 находится примерно на том же уровне, что и NVIDIA H100. Transformer Engine позволяет в режиме реального времени автоматически подбирать оптимальный баланс между производительностью и точностью вычислений.
Источник: Intel
Что примечательно для Intel Habana, так это то, что не требуется никакой оптимизации — стандартные модели работают прямо «из коробки». Intel отметила, что улучшила результаты на 10 % по сравнению с прошлым раундом. Но главное то, что теперь для ускорителей доступна поддержка PyTorch, что должно положительно сказаться на их популярности. Если, конечно, Intel в сложившейся ситуации ради экономии не забросит данные продукты.
Источник: MosaicML
Наконец, стоит обратить внимание на стартап MosaicML, основанный выходцем из Nervana (впоследствии Intel). Компания в очередной раз провела бенчмарки в категории Open и показала отличные результаты. Стартап продемонстрировал ускорение в 2,7 раза при тренировке BERT в сравнении с более ранними собственными результатами. При этом результаты при использовании MosaicML на A100 почти такие же, как при использовании фирменных инструментов NVIDIA на H100. Но в случае MosaicML никакой дополнительной ручной оптимизации со стороны пользователя не требуется.
Источник новости: servernews.ru



