




Исследователи Meta* Research представили нейросеть, которая анимирует 3D-аватары, используя запись голоса. Модель машинного обучения подстраивает под разговор мимику и жесты, опираясь на эмоциональную окраску голоса. Особенность метода в том, что система использует сразу два типа нейросетей для получения более гибкого результата.
Для анимации 3D-модели используются три модели: для анимации лица, предиктора позы и анимации жестов. Отмечается, что сперва система генерирует движение лицевых мышц, используя в качестве входных данных аудио и предварительно обученный регрессор губ. Для генерации позы система получает на вход аудио и авторегрессивно выдаёт направляющие позы с частотой 1 кадр в секунду. Для этого используется нейросеть Кохонена.
Для полноценной генерации связанных между собой движений используется диффузионная модель машинного обучения. На вход ей передают аудио и ранее полученные данные. На этом этапе хронометраж итогового видео заполняется движениями с частотой обновления 30 кадров в секунду. На финальном этапе сгенерированные движения лица и тела передаются в систему рендеринга 3D-аватаров.
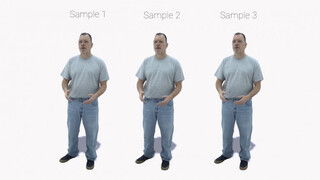
Исследователи отмечают, что итоговые рендеры получаются фотореалистичными, а благодаря использованию диффузионной модели вместе с нейросетью Кохонена удаются получить несколько вариантов на выбор. Кроме того, разработчики считают, что полученный метод генерирует более динамичные и выразительные движения фотореалистичных аватаров.
Код проекта открыт и опубликован на GitHub. В репозитории находится инструкция по локальному запуску модели и сценарии для обучения моделей с нуля. Для тестов исследователи подготовили демонстрацию на портале Colab.
Meta Platforms*, а также принадлежащие ей социальные сети Facebook** и Instagram**:
* — признана экстремистской организацией, её деятельность в России запрещена
** — запрещены в России
Источник новости: habr.com



