




данные актуальны на 01 октября 2024
Файнтюн выполнен по методу RLHF (в частности REINFORCE) и показывает хороший результат для задач рассуждений и логики.
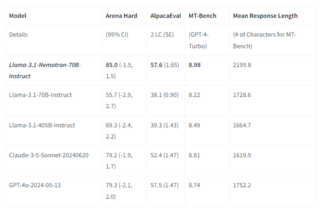
Новая модель занимает высокое место в метрике Arena Hard, включающая в себя 500 сложных запросов от пользователей, в основном это задачи логики, загадок, рассуждений и математики. В этих задачах эта модель показывает себя лучше чем Llama-3.1 размером 405B или версии gpt-4o от 13 мая.
При этом модель не обучалась для написания кода, поэтому тут модель показывает себя на 3.7% хуже, чем просто Llama-3.1-70B.Бенчмарк Aider’s code editing benchmark
Размер контекста такой же как и у Llama 3.1 и составляет 128k токенов.
Карточка модели: https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
gguf файлы: https://huggingface.co/bartowski/Llama-3.1-Nemotron-70B-Instruct-HF-GGUF
Демо онлайн:
https://build.nvidia.com/nvidia/llama-3_1-nemotron-70b-instruct
https://huggingface.co/chat/models/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
https://lmarena.ai/ (выбрать 2 вкладку side-by-side и найти там нужную модель)
Как запускать модели локально на обычном ПК (без видеокарты просто на CPU, на видеокартах включая 8Гб памяти, и на AMD видеокартах).
Источник новости: habr.com



