




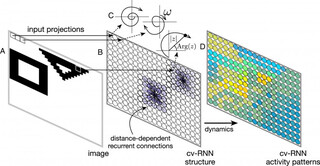
Схематическое представление cv-RNN. (A) Входное изображение. Каждый пиксель проецируется на один узел в cv-RNN. (B) Узлы в cv-RNN организованы в двумерный лист, где веса рекуррентных связей (фиолетовые) убывают по гауссиане с расстоянием между узлами Eq. 4. (C) Активность каждого узла описывается фазой Arg ( 𝑧 ) и амплитудой | 𝑧 | в комплексной плоскости. Входы от пикселей изображения модулируют собственную частоту 𝜔 соответствующего узла. (D) Входы изображений взаимодействуют с рекуррентной динамикой cv-RNN, создавая пространственно-временные паттерны активности в сети, которые могут быть использованы для сегментации изображений.
Западные исследователи разработали новую методику, позволяющую с помощью математики понять, как именно нейронные сети принимают решения.
Многие современные технологии, от цифровых помощников Siri и ChatGPT до медицинской визуализации и самоуправляемых автомобилей, основаны на машинном обучении. Однако логику «рассуждений» нейронных сетей, лежащих в основе этих систем машинного обучения, трудно понять. Исследователи часто называют ИИ «чёрными ящиками» среди исследователей.
«Мы создаём нейронные сети, которые могут выполнять конкретные задачи, оставляя себе возможность решать уравнения, управляющие их деятельностью, — говорит Лайл Мюллер, профессор математики и директор Западной лаборатории сетевых наук Филдса, входящей в состав недавно созданного Центра сотрудничества Филдса и Запада. — Это математическое решение позволяет нам "открыть чёрный ящик" и понять, как именно сеть делает то, что она делает». Пространственно-временная динамика, создаваемая cv-RNN. (A) Изображение, взятое из набора данных 2Shapes (см. Материалы и методы, Исходные изображения и наборы данных), подаются на осцилляторную сеть путём модуляции собственных частот узлов 𝜔 . Образцы фазовой динамики в рекуррентном слое во время переходного периода показывают, что узлы запечатлевают визуальное пространство, генерируя три различных пространственно-временных паттерна: один для узлов, соответствующих фону во входном пространстве, другой для узлов, соответствующих квадрату во входном изображении, и, наконец, для узлов, соответствующих треугольнику во входном пространстве. (B) Изображение, взятое из набора данных MNIST&Shapes, вводится в динамическую систему. Возникают три различных пространственно-временных паттерна: один для узлов, соответствующих фону в пространстве визуального ввода, другой для узлов, соответствующих треугольнику в пространстве ввода, и, наконец, для узлов, соответствующих рукописному трёхзначному символу
Западная команда, в которую вошли Мюллер, постдокторанты Луиза Либони и Роберто Будзински, а также аспирант Алекс Буш, впервые продемонстрировала это новое достижение на задаче сегментации изображений — фундаментальном процессе в компьютерном зрении, когда системы машинного обучения разделяют изображения на отдельные части, например, отделяют объекты на изображении от фона.
Начав с простых геометрических фигур, таких как квадраты и треугольники, они создали нейронную сеть, способную сегментировать эти базовые изображения.
Затем Мюллер и его коллеги использовали математический подход, который они ранее разработали для изучения других сетей, чтобы исследовать, как новая сеть выполняет задачу сегментации при анализе этих простых изображений.
Математический подход позволил команде точно понять, как происходит каждый шаг вычислений. К некоторому удивлению, команда обнаружила, что сеть также может сегментировать — или видеть и интерпретировать — несколько естественных изображений, таких как фотографии белого медведя, идущего по снегу, или птицы в дикой природе.
«Упростив процесс, чтобы получить математическое представление, мы смогли построить сеть, которая была более гибкой, чем предыдущие, а также хорошо справлялась с новыми входными сигналами, которые она никогда не видела», — говорит Мюллер, сотрудник Западного института нейронаук.
Источник новости: habr.com



